¶ Sentiment Analysis
AI can classify emotions from text into 3 categories: positive, neutral, or negative.
Beta version: The platform is in a development stage of the final version, which may be less stable than usual. The efficiency of platform access and usage might be limited. For example, the platform might crash, some features might not work properly, or some data might be lost.
¶ Training model
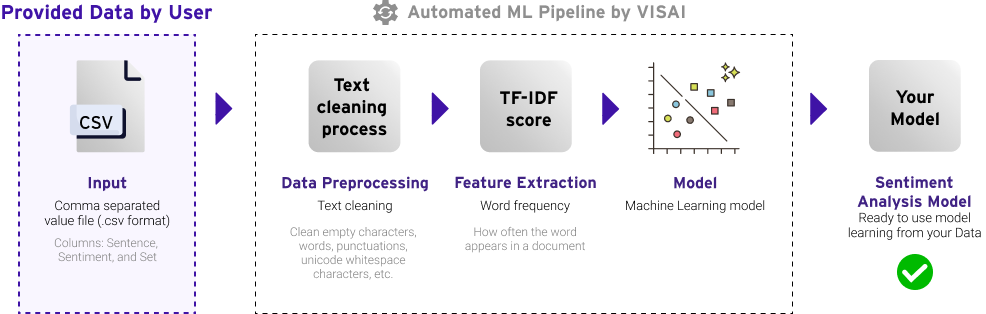
For “Customized AI" mode: you are required to prepare only a dataset for training in case you want to train your model.
¶ Input
The input data should be in a format of ‘comma separated value’ file (.csv format). In other words, the input data is shown as a table data separated by “,” or a comma sign. After having uploaded the dataset, a user is required to select types of data for each column. The detail of possible column types is presented as follows:
- Sentence contains a sentence of text.
- Sentiment contains a corresponded label, which can be “Positive”, “Neutral”, or “Negative”.
* This model version only supports one sentiment per sentence - Train/Test (Optional) identifies the purpose of each row used in the training process, which can be “Train” and “Test” (for more detail about splitting dataset, please go to ‘Train/Test split’ section).
* If the Train/Test column does not assign, ACP will automatedly split a dataset into 70:30 (Train: Test). You can adjust the ratio in the "Train/Test Split" on “Build new model” process

¶ The quality of data
Since sentiment analysis is a statistical-based machine learning model, an optimal amount of training data is required to ensure model performance. Moreover, the quality of data as well as the number of samples per class is important. If the model is trained on a dataset that is too small, the model could potentially overfit, which might drop model performance. Likewise, when the number of samples per class is unbalanced, there could be mismatches between sentences and their labels (e.g., 90% pos, 5% neg, 5% neu). In that case, the model will be most inclined to poorly predict minority class.
¶ How to prepare input data
- Collect sentences and sentiments from your existing source.
- Filter out sentences with following criteria:
- Contain emojis/emoticons more than half of its characters.
- Contain foreign characters more than 5 contiguous characters.
- Illegible language including randomly written words.
- Recheck sentiments with the following guideline:
- There is a corresponding sentiment for each sentence, if not, remove entire row out.
- There is the only one sentiment per sentence, if not, remove entire row out.
- The sentiment should relate the content of its sentence, if not, then reannotate sentiment.
- The amount of data per sentiment should be enough, if not, loop back to first step to collect more data.
- Format data to our required format; see in “input” section.
¶ Data preprocessing
Prior to extracting features and feed vectors to a model, the text will be preprocessed according to the following rules:
- Remove HTML tags
- Reorder vowels to correct Thai word misspelling
- Format spaces and new lines appropriately
- Remove brackets
- Format URL links
- Format repeated text, words
- Cast all texts to be lowercase (to reduce number of words)
- Ungroup all emojis
All these preprocessing methods are done by using PythaiNLP library. Additionally, we also use Thai word tokenization model called newmm which can also be found in The PythaiNLP library.
¶ Feature extraction
In this model pipeline, the TF-IDF was used as a feature extractor. The goal of feature extraction is to convert the text sentence into a set of numbers that we called “feature”. To do so, the feature extractor counts the word frequency of each sentence and weights each count by the frequency of the whole documents. This ensures that the feature would take some stop words (e.g., a, an, the) into account when extracting features. Moreover, the TF-IDF features are rescored via naïve bayes probability to enrichen the information of each word. This process of rescoring features is called Naïve Bayes features.
¶ Model
The sentiment analysis model uses a Machine Learning model calculated from TF-IDF to predict the probability of each sentiment. The model tries to maximize the likelihood of each sample. Thus, the model is simple, fast, but yields a good performance.
¶ Model evaluation
For a sentiment analysis, we use accuracy, F1 score, precision, recall and confusion matrix to evaluate a model. Generally, higher accuracy, F1 score, precision, and recall mean better performance.
¶ Using approach

¶ Input
the sentiment model receives list of sentences as an input. The API JSON input format is shown below.
{
“inputs”: [
“sentence-1”
, “sentence-2”
, “sentence-3”
…
]
}
¶ Output
The response of the sentiment model API will be a list of JSON where each element is another key-value object that contains its sentence and its predicted probability of each class. The API response would be in the following JSON format:
[
{
“sentences”: <sentence-1>,
“results”: {
“Positive”: <prob-positive-of-sentence-1>,
“Neutral”: <prob -neutral-of-sentence-1>,
“Negative”: <prob-negative-of-sentence-1>
}
},
…
]