¶ Evaluation Metrics
Beta version: The platform is in a development stage of the final version, which may be less stable than usual. The efficiency of platform access and usage might be limited. For example, the platform might crash, some features might not work properly, or some data might be lost.
¶ Classification metrics
The metrics are designed to measure a classification model's performance. The classification metrics are listed below:

¶ Accuracy
Accuracy is the ratio of correctly predicted observations to the total observations. The accuracy indicates the percentage of the corrected prediction.
¶ Precision
Precision is the ratio of correctly predicted observations of a specific class to the total predicted observations of a specific class. It is a measure of how many of the positive predictions made are correct out of all predicted positive.
¶ Recall / Sensitivity / True positive rate (TPR)
Recall / Sensitivity / TPR is the ratio of correctly predicted observations of a specific class to the total observations of a specific class. It is a measure of how many of the actual positives are captured through positive labeling.
¶ False positive rate (FPR)
FPR is the ratio of actual negative predicted as positive to the total actual negative. It is a percentage of negative cases that are classified as positive.
¶ F1 score
F1 score is the weighted average of precision and recall. It is a harmonic means of precision and recall.
¶ Area Under Receiver operating characteristic (AUROC)
AUROC is an area under ROC curve which is plotted between TPR and FPR to measure the ability of a model to distinguish between positive and negative classes. The higher AUROC means the model’s ability to distinguish.
¶ Confusion matrix (CM)
F1 score is the weighted average Confusion matrix (CM) represents the results from the model by reporting the numbers which match between the prediction and actual results in every class. It is usually presented in a table or a matrix. Normally confusion matrix would be presented in three ways:
- Normalization (True): presented as the percentage of elements in each pair, calculated by the number of elements in each pair divided by the sum of elements on its “Actual class” axis. The sum of the percentage on each actual class is 1.00
- Without normalization (None): presented as the number of elements in each pair of specific “Actual class” and “Predicted class”
- Prediction: presented as percentage of elements in each pair, calculated by the number of elements in each pair divided by the sum of elements on its “Predicted class” axis. The sum of the percentage on each predicted class is 1.00
¶ Transcribing text sentence metrics
In some machine learning tasks, the target prediction is a series of text, or a sentence. For example, automatic speech recognition (ASR) transcribes audio into a sentence, and Optical Character Recognition (OCR) decodes texts from an image. There are three types of errors to consider:
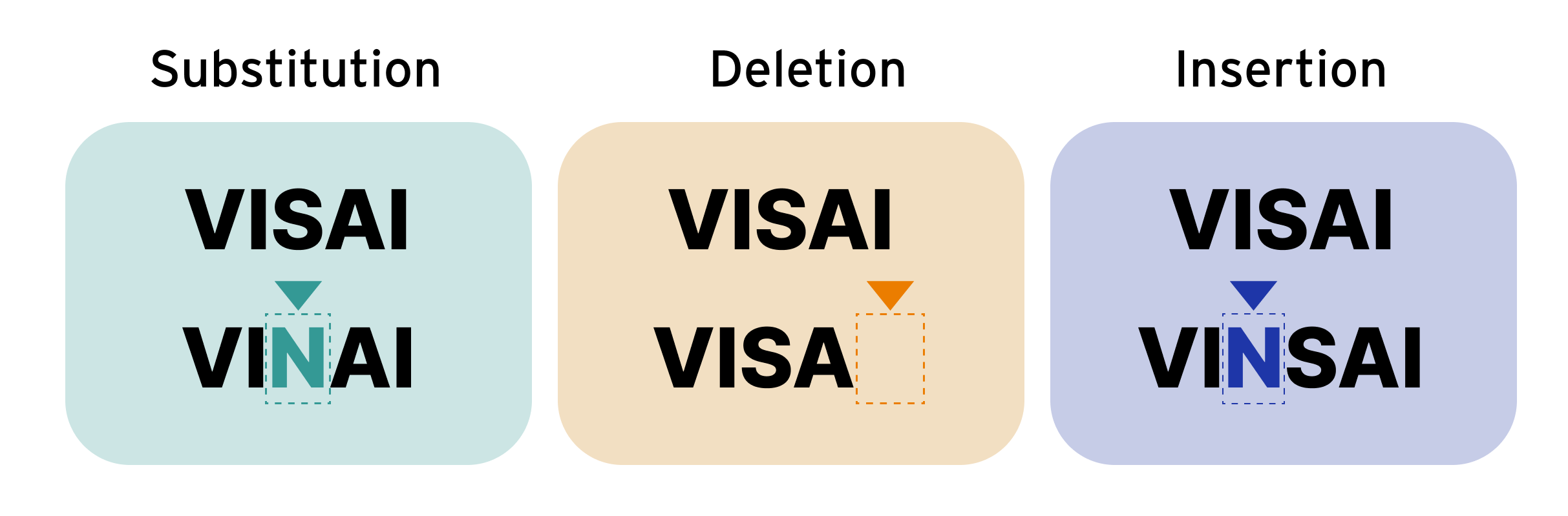
- Substitution error (S): Misspelled characters/words
- Deletion error (D): Lost or missing characters/words
- Insertion error (I): Incorrect inclusion of characters/words
Typically, we use two metrics to evaluate the predicted sentence:
¶ Word Error Rate (WER)
Calculate the error of the sentence by measuring how many words were deleted, inserted, or substituted from the ground truth. The lower the value is, the better the performance of a model becomes. A WER of 0 is a perfect score.
¶ Character Error Rate (CER)
Similar to word error rate, but the difference is the unit used to calculate the error. WER uses word-level error, while CER uses character-level error. The lower the value is, the better the performance of a model becomes. A CER of 0 is a perfect score.
¶ Edit distance
The edit distance metric is a widely used method in OCR tasks. It calculates the distance in characters needed to change one sentence (prediction) into another (label). Let's examine the example provided below.
Label: Mr. Sawasdee Wanchan
Prediction: Mr Sawasdea Waanchan
In this example, the edit distance is 3 as there are
- 1 insertion of the character
- 1 substitution of the character
- 1 deleted character
In other words, it took 3 characters correction to change from the predicted sentence to the Label (Ground truth) sentence. Although some people may use a normalized edit distance over edit distance.
¶ Speaker evaluation metric
¶ Diarization Error Rate (DER)
It quantifies the overall performance of the system in segmenting an audio recording into individual speaker segments. DER is calculated based on the number of errors made by the system in terms of speaker boundaries, speaker identities, and speech/non-speech segmentation. Lower DER values indicate better performance, as it means fewer errors were made in the diarization process.
where
- TotalGroundTruth: the overall duration of the ground truth segments.
- Miss: the duration of segments in the ground truth that are labeled as speech but are not detected in the prediction.
- False Alarm: The duration of segments in the prediction that are identified as speech but are not present in the ground truth.
- Confusion/SpeakerError: The duration of segments that are assigned to different speakers in prediction and ground truth.
¶ Translation evaluation metric
¶ BLEU Score
BLEU (BiLingual Evaluation Understudy) is a metric for evaluating a machine translated sentence to a reference sentence. The scores are between 0 and 100. A score of 100 means a perfect match result, while a score of 0 means a perfect mismatch result.
The steps to calculate the BLEU score are as follows:
- Compute a Geometric Average Precision Scores
A geometrix average of the modified n-gram precisions can be computed for different values up to N and weight values. The formula is as below:
Where is the proportion of n-grams that match the reference sentence, is a positive weight. In our baseline evaluation, we use and uniform weights w_{n} = \frac{1}
- Compute a Brevity Penalty (BP)
BP is employed to penalize translated sentences that are too short compared to their reference sentence’s length.
Where is the number of words in the translated sentence, is the number of words in the reference sentence.
- Calculate the BLEU score
BLEU score is calculated by multiplying the Brevity Penalty with the Geometric Average of the Precision Scores.
¶ N-gram
The n-gram is typically used in a text or speech processing. It is a sequence of N consecutive words in a sentence.
For example, for the sentence “How high will the temperature climb?”, then the n-gram would be:
| N-gram | Example |
| 1-gram (unigram) | “How”, “high”, “will”, “the”, “temperature”, “climb”, “?” |
| 2-gram (bigram) | “How high”, “high will”, “will the”, “the temperature”, “temperature climb”, “climb?” |
| 3-gram (trigram) | “How high will”, “high will the”, “will the temperature”, “the temperature climb”, “temperature climb?” |
| 4-gram | “How high will the”, “high will the temperature”, “will the temperature climb”, “the temperature climb?” |
¶ N-gram precisions
Precision is a metric to measure the number of words in the translated sentence that also occur in the reference sentence.
¶ Regression metrics
In this task we predict values in continuous number. Terminologies involved in regression are detailed in the table.
- Actual value (y): the actual values observed for samples
- Predicted value (ŷ): the values that model predicted
- Number of samples (n): sample count
The evaluation metrics for regression model:
¶ Mean absolute error (MAE)
"Mean of absolute errors of expected value"
MAE is calculated using absolute of error, less sensitive to outliers which might be a better choice than MSE.
¶ Mean square error (MSE)
"Mean of squared errors of expected value"
Due to MSE being calculated using squared of error, large errors will be emphasized, which makes it more sensitive in case of an outlier. In other words, since an outlier causes a high squared of error, the MSE will be high even though other errors are small.
¶ Root mean square error (RMSE)
"Square root of MSE"
RMSE is used more commonly than MSE because sometimes MSE value is difficult to compare as it can be too big.
¶ Mean absolute percentage error (MAPE)
"the average absolute percent error for each period minus actual values divided by actual values"
¶ Mean absolute scaled error (MASE)
the mean absolute error of the forecast values, divided by the mean absolute error of the in-sample one-step naive forecast.