¶ OCR General Document
The AI reads images of documents such as PDF, PNG, and JPG and converts them into text.
Beta version: The platform is in a development stage of the final version, which may be less stable than usual. The efficiency of platform access and usage might be limited. For example, the platform might crash, some features might not work properly, or some data might be lost.
¶ Training model

¶ Model
The OCR model consists of two main components: text detector, and text recognizer. The role of the text detector is to detect a location of text in an image. The model is trained with various documents with bounding boxes—localized text area. Then the text recognizer will transcribe each localized text area into actual text characters. The model was trained using standard cross-entropy loss using encoder-decoder transformers model. We use our internal synthetic data libraries with various data augmentation applied to approximate the multiple real world document distribution.
¶ Model evaluation
We use CER to evaluate an OCR General Document model. Generally, the lower CER means better performance.
¶ Using approach

¶ Input
The model receives raw images as an input. The API command input consists of multiparts or form-data (the filename and filepath) under HTTP Post request. The Input should be in PNG, JPEG, JPG, PDF formats. Users can upload multiple files to API with optional setting (Parameter) described below. The parameter can significantly impact the model's performance. Please note that the ACP OCR General Document allows a maximum of 15 pages per inference request.
{
“box_threshold”: box_threshold # float (Optional)
}
¶ Optional setting
- box_threshold
Adjusting the box_threshold value, ranged between 0 to 1, affects the detection of text in documents. A lower value allows the model to detect more bounding boxes, while a higher value reduces detection sensitivity. It is recommended to start with the default value of 0.4 and gradually increment the value by 0.1 until achieving the desired result for the document being used. If unspecified, the default value would be 0.4.
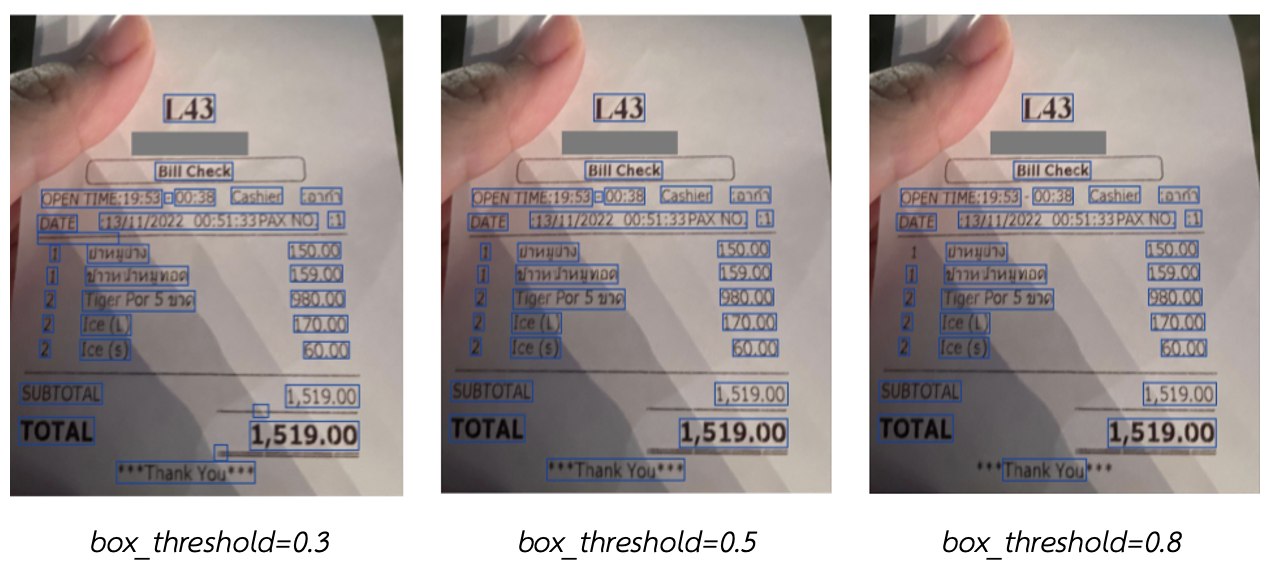
¶ Tips on using the model
The inputs can be raw images or document files. However, users can apply different preprocessing methods as described below to make the model perform better:
- Adjust the image’s brightness and contrast to make text easier to identify.
- Remove watermarks or edit until barely noticeable.
- Straighten the image. If done properly, the text should be horizontally aligned with the landscape.
- Threshold the image (box_threshold parameter). If done properly, the text should be clearer and easier to read.
¶ Output
The output of the OCR general document model is extracted text with a bounding box.
- Bounding box: each text box can be specified by 4-pixel coordinates (top-left corner, top-right corner, bottom-right corner, and cottom-left corner) on an image, where each coordinate can be represented by two numbers (x-axis location, and y-axis location).
- Extracted text: the extracted text in each box.
The API response would be in the following JSON format:
[
{
"filename": <file name>
, "status": <status>
, "results": [
{
"page": <page number>
, "data": [
{
"bbox": [
<the top left coordinates (x ,y)>
, <the top right coordinates (x ,y)>
, <the bottom right coordinates (x ,y)>
, <the bottom left coordinates (x ,y)>
],
"text": <Message>
}
]
, "fullText": <full message>
}
,{
....
}
]
}
]